使用PHP从文件中读取最后一行(即“tail”)的最佳方法是什么?
2022-08-30 08:12:50
在我的PHP应用程序中,我需要从许多文件(主要是日志)的末尾开始读取多行。有时我只需要最后一个,有时我需要几十个或几百个。基本上,我想要像Unix命令一样灵活的东西。tail
这里有关于如何从文件中获取最后一行的问题(但我需要N行),并给出了不同的解决方案。我不确定哪一个是最好的,哪个表现更好。
在我的PHP应用程序中,我需要从许多文件(主要是日志)的末尾开始读取多行。有时我只需要最后一个,有时我需要几十个或几百个。基本上,我想要像Unix命令一样灵活的东西。tail
这里有关于如何从文件中获取最后一行的问题(但我需要N行),并给出了不同的解决方案。我不确定哪一个是最好的,哪个表现更好。
在互联网上搜索,我遇到了不同的解决方案。我可以将它们分为三种方法:
file()tailfseek()我最终选择了(或写了)五个解决方案,一个天真的解决方案,一个作弊的解决方案和三个强大的解决方案。
tail 命令的,它有一个小问题:如果不可用,它就不会运行,即在非 Unix (Windows) 或不允许系统功能的受限环境中。tail所有解决方案都有效。从某种意义上说,它们从任何文件以及我们要求的任何行数返回预期的结果(除了解决方案#1,它可以在大文件的情况下打破PHP内存限制,不返回任何内容)。但哪一个更好?
为了回答这个问题,我运行了测试。这些事情就是这样完成的,不是吗?
我准备了一个100 KB的示例文件,将目录中的不同文件连接在一起。然后我写了一个PHP脚本,使用五个解决方案中的每一个来检索1,2,..,10,20,...100, 200, ..., 距文件末尾 1000 行。每个测试重复十次(大约5次×28次×10 = 1400次测试),以微秒为单位测量平均经过的时间。/var/log
我使用PHP命令行解释器在本地开发机器(Xubuntu 12.04,PHP 5.3.10,2.70 GHz双核CPU,2 GB RAM)上运行脚本。结果如下:
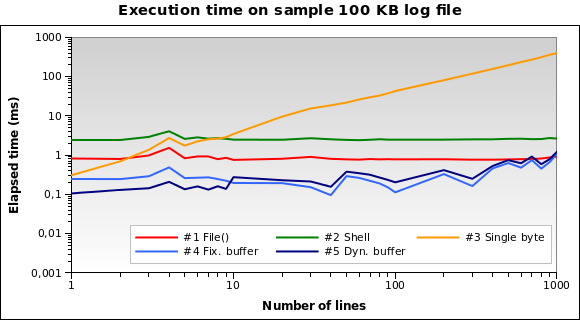
解决方案#1和#2似乎是更糟糕的。解决方案#3只有在我们需要阅读几行时才是好的。解决方案#4和#5似乎是最好的。请注意动态缓冲区大小如何优化算法:由于减少了缓冲区,因此对于几行,执行时间会稍短一些。
让我们尝试使用更大的文件。如果我们必须读取 10 MB 的日志文件,该怎么办?
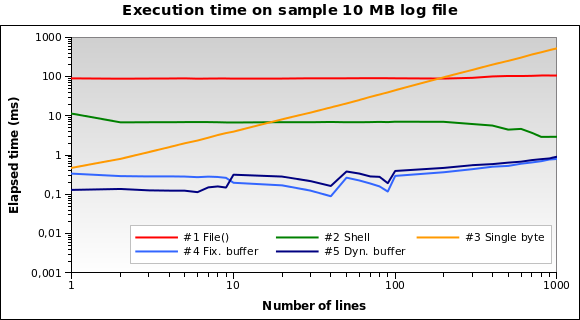
现在解决方案#1是迄今为止最糟糕的解决方案:实际上,将整个10 MB文件加载到内存中并不是一个好主意。我也在1MB和100MB文件上运行测试,实际上情况相同。
对于微小的日志文件?这是一个 10 KB 文件的图表:
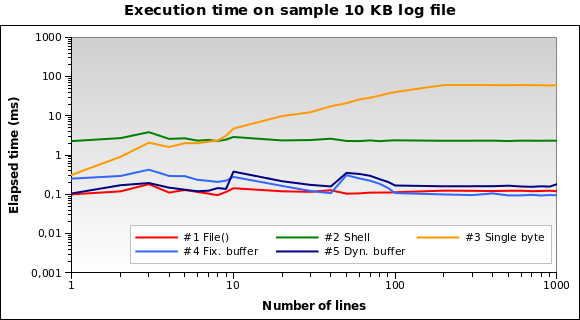
解决方案#1现在是最好的!将10 KB加载到内存中对于PHP来说并不是什么大问题。此外,#4和#5表现良好。但是,这是一个边缘情况:10 KB日志意味着大约150/200行...
您可以在此处下载我的所有测试文件,来源和结果。
对于一般用例,强烈建议使用解决方案#5:适用于每种文件大小,并且在读取几行时性能特别好。
如果您应该读取大于 10 KB 的文件,请避免使用解决方案 #1。
对于我运行的每个测试,解决方案#2和#3都不是最好的:#2永远不会在不到2ms的时间内运行,并且#3受到您询问的行数的严重影响(仅在1或2行中效果很好)。
这是一个修改后的版本,也可以跳过最后一行:
/**
* Modified version of http://www.geekality.net/2011/05/28/php-tail-tackling-large-files/ and of https://gist.github.com/lorenzos/1711e81a9162320fde20
* @author Kinga the Witch (Trans-dating.com), Torleif Berger, Lorenzo Stanco
* @link http://stackoverflow.com/a/15025877/995958
* @license http://creativecommons.org/licenses/by/3.0/
*/
function tailWithSkip($filepath, $lines = 1, $skip = 0, $adaptive = true)
{
// Open file
$f = @fopen($filepath, "rb");
if (@flock($f, LOCK_SH) === false) return false;
if ($f === false) return false;
if (!$adaptive) $buffer = 4096;
else {
// Sets buffer size, according to the number of lines to retrieve.
// This gives a performance boost when reading a few lines from the file.
$max=max($lines, $skip);
$buffer = ($max < 2 ? 64 : ($max < 10 ? 512 : 4096));
}
// Jump to last character
fseek($f, -1, SEEK_END);
// Read it and adjust line number if necessary
// (Otherwise the result would be wrong if file doesn't end with a blank line)
if (fread($f, 1) == "\n") {
if ($skip > 0) { $skip++; $lines--; }
} else {
$lines--;
}
// Start reading
$output = '';
$chunk = '';
// While we would like more
while (ftell($f) > 0 && $lines >= 0) {
// Figure out how far back we should jump
$seek = min(ftell($f), $buffer);
// Do the jump (backwards, relative to where we are)
fseek($f, -$seek, SEEK_CUR);
// Read a chunk
$chunk = fread($f, $seek);
// Calculate chunk parameters
$count = substr_count($chunk, "\n");
$strlen = mb_strlen($chunk, '8bit');
// Move the file pointer
fseek($f, -$strlen, SEEK_CUR);
if ($skip > 0) { // There are some lines to skip
if ($skip > $count) { $skip -= $count; $chunk=''; } // Chunk contains less new line symbols than
else {
$pos = 0;
while ($skip > 0) {
if ($pos > 0) $offset = $pos - $strlen - 1; // Calculate the offset - NEGATIVE position of last new line symbol
else $offset=0; // First search (without offset)
$pos = strrpos($chunk, "\n", $offset); // Search for last (including offset) new line symbol
if ($pos !== false) $skip--; // Found new line symbol - skip the line
else break; // "else break;" - Protection against infinite loop (just in case)
}
$chunk=substr($chunk, 0, $pos); // Truncated chunk
$count=substr_count($chunk, "\n"); // Count new line symbols in truncated chunk
}
}
if (strlen($chunk) > 0) {
// Add chunk to the output
$output = $chunk . $output;
// Decrease our line counter
$lines -= $count;
}
}
// While we have too many lines
// (Because of buffer size we might have read too many)
while ($lines++ < 0) {
// Find first newline and remove all text before that
$output = substr($output, strpos($output, "\n") + 1);
}
// Close file and return
@flock($f, LOCK_UN);
fclose($f);
return trim($output);
}




